

Umetna inteligenca je tu. Pa smo pripravljeni nanjo?
Čeprav je besedno zvezo umetna inteligenca ameriški pionir računalništva John McCarthy skoval in uvedel že leta 1956, je zadnje desetletje tisto, ki je poskrbelo, da je postala vseprisotna. Skoraj ne mine dan, da je ne bi slišali, prebrali ali o njej govorili. Za njen dokončni preboj v vsakdan običajnih uporabnikov osebnih računalnikov je gotovo odločilna četrta izdaja aplikacije ChatGPT. Ta je s svojo enostavnostjo in dostopnostjo poskrbela za vsesplošno rabo tehnologije, ki je dotlej bivala pretežno v tehniških in znanstvenih okoljih. Zdaj pa je nenadoma silovito izbruhnila v naš vsakdan in prav nič ne kaže, da ga bomo še kdaj zmogli brez nje.
Pri tem pa se le malokdo ukvarja s pomembnimi vprašanji, ki nam jih UI postavlja – pri čemer imamo v mislih tako tehnične in tehnološke kot tudi etične dileme. In le malo uporabnikov dejansko ve, za kakšne sisteme pravzaprav gre in kakšne izzive prinašajo. Človeštvo se s čim podobnim preprosto še ni soočalo, zato lahko situacijo primerjamo s srečanjem z zunajzemeljsko inteligenco.
O čem sploh govorimo, ko govorimo o umetni inteligenci? Evropski parlament jo je definiral tako: »Umetna inteligenca je sposobnost stroja, da posnema človeške sposobnosti, kot sta logično razmišljanje, učenje, načrtovanje in ustvarjalnost.« (Teme Evropskega parlamenta, 2020) Pogovorno torej termin umetna inteligenca uporabljamo za sisteme, ki posnemajo miselne postopke človeškega uma – zmožnosti učenja in reševanja problemov. Za učenje je v prvi vrsti pomembno zadostno število podatkov, torej virov, na podlagi katerih tvorimo zaključke. Povsem enako velja za umetno inteligenco.
Tudi zanjo je prvi pogoj za delovanje dovolj veliko število podatkov in vzorcev, z obdelavo katerih se sistem uči ter na njihovi podlagi sprejema odločitve in/ali sintetizira odgovore. V primeru prej omenjene aplikacije ChatGPT večinski del nabora potrebnih podatkov predstavljajo vsa javno dostopna besedila, ki so bila do določenega trenutka objavljena na svetovnem spletu. S pomočjo teh besedil in podatkov sistem tvori nova besedila oziroma odgovore na vprašanja uporabnikov, vse skupaj pa temelji na že obdelanih vzorcih – informacijah ali podatkih, ki jih je sistem pred tem uporabil za učenje.
Tu trčimo v največji izziv, ki ga pred nas postavljajo sistemi umetne inteligence. Za obdelavo zadostnega števila informacij – govorimo o velikanskih količinah podatkov – potrebujejo izredno zmogljive sisteme oziroma opremo, ki je sposobna vse te informacije oziroma podatke obdelati v izjemno kratkem času. V zadnjih letih smo zato priča skokovitemu razvoju namenskih IT sistemov z visokimi procesorskimi zmogljivostmi, kakršne so še do nedavnega veljale za nepredstavljive. Visoka zmogljivost oziroma procesorska moč – z njo pa tudi potrebna kapaciteta hranjenja – pa seveda prinašata veliko potrebo po električni energiji. In visoka poraba električne energije nujno pomeni veliko generirane toplote.
Povedano drugače: sistemi, ki omogočajo delovanje umetne inteligence, so zasnovani drugače kot običajni ITK sistemi. Delujejo sicer na podobnih temeljih, a omogočajo bistveno večje procesorske in komunikacijske zmogljivosti ter bistveno več hranjenja podatkov. Zato prinašajo bistveno drugačne in višje zahteve za okolje, v katerega so nameščeni.
In že smo pri naslednjem izzivu. Hitro namreč postane jasno, da obstoječa infrastruktura oziroma nabor IKT opreme nista ustrezna, saj ne omogočata namestitve visoko zmogljivih sistemov, ki jih za svoje delovanje zahteva UI. Četudi danes velika večina sistemov umetne inteligence še deluje v namenskih podatkovnih centrih, skrbniki in uporabniki upravičeno pričakujejo, da se bodo prav kmalu preselili tudi v manjše centre, torej neposredno k uporabnikom.
Kaj so novi izzivi
Sistemi umetne inteligence torej zelo kmalu ne bodo več delovali le kot veliki jezikovni modeli ali na podlagi informacij, ki so zanimive zgolj za širok krog uporabnikov. Selili se bodo tudi v okolja specifičnih, manjših uporabnikov. Eno takšnih so gotovo poslovna okolja podjetij, tudi malih in srednjih. Napovedovanje in optimizacija porabe električne energije, logistika, napovedovanja prometnih konic in zastojev, terenske analize, analize in napovedovanja tržnih gibanj, analize in napovedovanje vedenja kupcev... Načinov uporabe in razlogov za integracijo UI v poslovne modele podjetij je nešteto. Bistvena prednost uporabe umetne inteligence je namreč, da lahko obdela neprimerno več informacij in podatkov ter na osnovi tega učenja sprejme odločitve ali predlaga optimalne postopke in procese bistveno hitreje kot ljudje. Zato bo uporaba UI sistemov v poslovnem in gospodarskem okolju nujnost, če bodo podjetja želela ohraniti ali pridobiti konkurenčne prednosti. To pa pomeni, da bodo morali biti sistemi in infrastruktura za delovanje umetne inteligence zelo hitro nameščeni tudi v podatkovnih centrih malih uporabnikov in podjetij. Pa so na to pripravljeni? Odgovor je na dlani: niso.
In kaj bo treba storiti, da bodo? Preden ponudimo odgovor na to vprašanje moramo razumeti, s čim sploh imamo opravka. Zgovoren primer so obremenitve. Doslej so bile povprečne obremenitve sistemskih omar v podatkovnih centrih med 5 in 10 kW na posamezno omaro. To pomeni, da je bila v vsaki sistemski omari v povprečju nameščena ITK oprema za skupno priključno moč med 5 in 10 kW, v redkih primerih do 20 kW. Vsa ta oprema je bila povečini zračno hlajena – za hlajenje je torej uporabljen zrak, ohlajen na temperaturo med 22 in 24 stopinj Celzija. Že prej smo ugotovili, da sistemi umetne inteligence uporabljajo izjemno zmogljive procesorje in druge kapacitete. To pomeni veliko večjo porabo električne energije ter posledično veliko toplotno breme za podatkovne centre. Kot primer poglejmo sistem Nvidia DGX B200. Vsebuje 8 procesorjev Nvidia Blackwell GPU z ostalo potrebno periferijo. Električna in toplotna moč takšnega sistema je cca 14kW, v eno sistemsko omaro pa jih lahko namestimo do 4. To pomeni, da lahko električna in toplotna obremenitev ene sistemske omare doseže do 56 kW. Takšna obremenitev je s klasičnimi tehnikami absolutno neobvladljiva. Še večje izzive prinašajo drugi, zaradi izjemno visokih moči že povečini neposredno vodno hlajeni sistemi, kjer moči dosegajo od 130 do celo 400 kW na eno sistemsko omaro, že v nekaj letih pa bo ta številka poskočila celo do 1MW.
Zaradi vsega tega lahko preprosto sklepamo dvoje. Prvič, da podatkovni centri, kakršne poznamo danes, niso pripravljeni na namestitev sistemov, ki podpirajo in omogočajo UI. In drugič, da se bo kljub možnosti za uporabo sistemov v »oblaku« večina skrbnikov in uporabnikov že kmalu srečala s potrebo po namestitvi lastnih sistemov. Pri tem čas nikakor ni zanemarljiv. Nagel razmah UI, ki smo mu priča pravkar, pomeni, da moramo odgovore na vprašanja, kako bomo obstoječe podatkovne centre pripravili na vse nove izzive, poiskati že danes. Že danes pa moramo začrtati tudi strategije za ustrezno načrtovanje future-ready podatkovnih centrov, ki bodo lahko sledili razvoju in rastočim zahtevam UI ter tudi v prihodnosti zagotavljali izkoriščanje vseh potencialov, ki jih ponuja.
Pri tem ne smemo pričakovati, da bodo zahteve po energetski učinkovitosti ostale enake današnjim. Zagotovo bodo višje, uporabniki pa bodo pripravljeni investirati le v sisteme, ki bodo energetsko čim bolj učinkoviti. Ob tem uporabniki za delovanje dveh vrst opreme, klasične ITK opreme in energetsko zmogljivih UI sistemov zagotovo ne bodo želeli imeti nameščenih ločenih podatkovnih centrov, temveč le enega, ki bo moral zagotavljati delovanje obeh vrst opreme in sistemov.
Hibridni podatkovni centri
Zato se pojavlja nova vrsta podatkovnih centrov – hibridni podatkovni centri, ki sočasno gostijo običajne ITK sisteme z nizko energetsko gostoto in UI sisteme z visoko gostoto. Tudi ti se za zdaj še zanašajo na zračno hlajenje, nekaj z običajno gostoto, nekaj pa z visoko gostoto. Že kmalu pa lahko pričakujemo povečanje gostote do mere, da samo zračno hlajenje ne bo več zadoščalo. Zato se bodo morali podatkovni centri znova preleviti – postali bodo pravi hibridni centri. Da bodo kos vsem zahtevam, bo treba spremeniti način razmišljanja ter sprejeti nove tehnologije in principe, ki so bili še nekaj let nazaj malone nepredstavljivi. Tu mislimo predvsem na neposredno tekočinsko hlajenje, ki ga moramo obravnavati kot nujno dejstvo. Gre za tehnologijo, s katero so neposredno tekočinsko hlajeni polprevodniški elementi (procesorji, pomnilnik ...) v strežnikih. Praktično to pomeni, da so strežniki in druga oprema priključeni na namenske tekočinske hladilne sisteme. S temi sistemi lahko iz opreme odvedemo kar do 95 % toplote. Če za primer vzamemo 130 kW generirane toplote, to pomeni, da je 123,5 kW odvedemo s tekočino, preostalih 6,5 kW pa z zrakom.
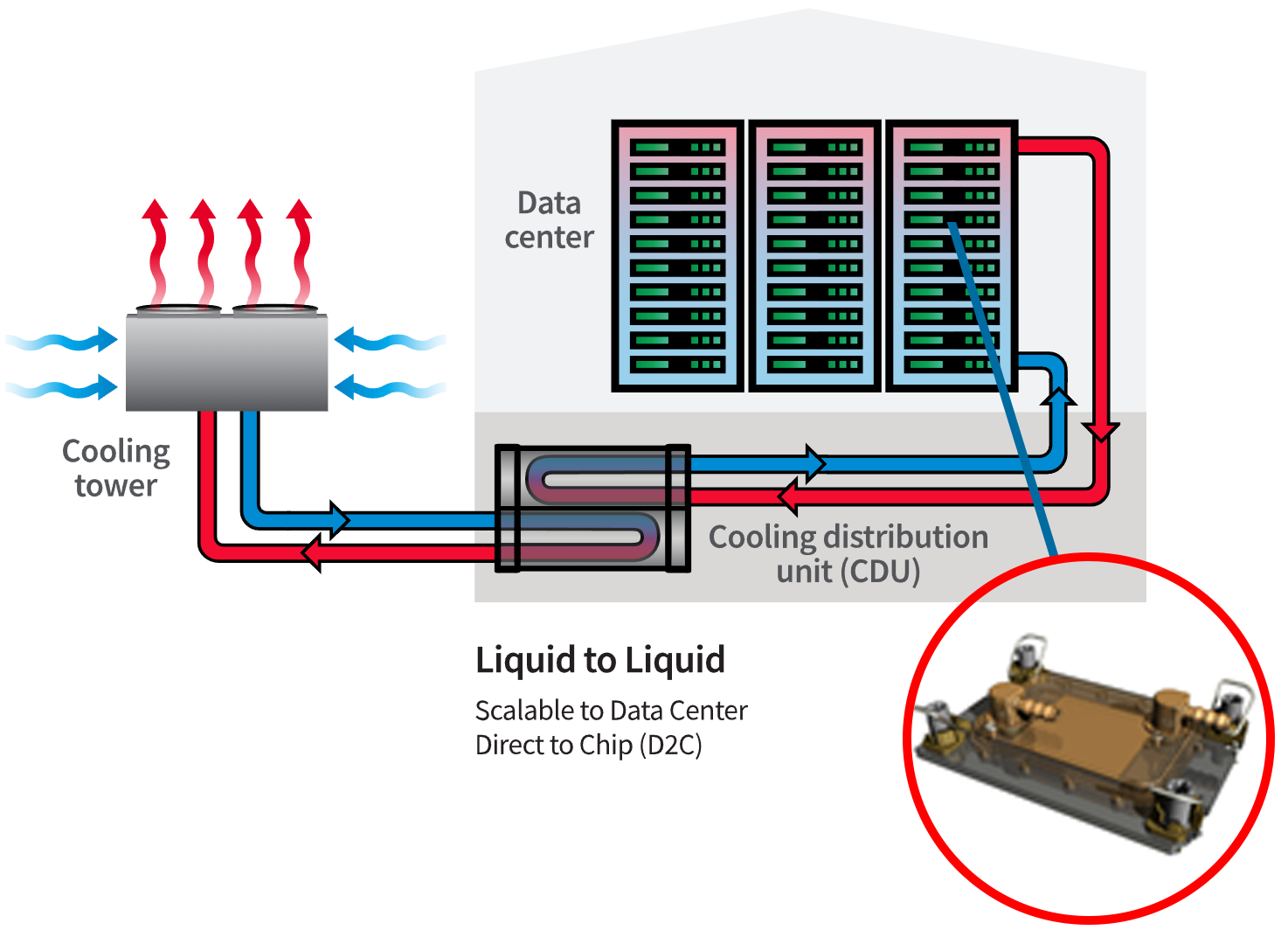
Hibridni centri bodo imeli pripravljene cevne razvode za sisteme tehničnega hlajenja, ki bodo omogočali enostaven priklop novih sistemov na cevovode. Hlajenje tekočine bo energetsko najučinkovitejše, saj so novi temperaturni režimi takšni, da omogočajo kompresorja prosto hlajenje praktično vse leto. Tipični vodni režim za neposredno vodno hlajene sisteme je 35/45 stopinj Celzija.


Poleg hlajenja bo v novih podatkovnih centrih popolnoma spremenjen tudi način napajanja. Vedno manj bo klasičnih PDU enot, poskočila pa bo raba namenskih PDU enot visoke moči (43, 69, 85 kW). Za razvod električne energije bodo uporabljeni namenski zbiralčni sistemi, ki omogočajo hitro prekonfiguriranje ter prilagoditev na nove razvode. Ob opisanih bodo novi podatkovni centri deležni še cele vrste drugih prilagoditev. Omenimo napajalne in hladilne sisteme, suhe hladilce in/ali adiabatne hladilne sisteme ter stolpe, pa tudi možnost izkoriščanja odpadne toplote, kar bo z visokimi zmogljivostmi in temperaturnimi režimi postalo mnogo realnejše.

Kako se pripraviti na hibridne podatkovne centre
Za pripravo na nove tehnologije, ki nezadržno prihajajo, bomo morali nujno postati mnogo bolj odprti za novosti. Poiskati bomo morali odgovore na vprašanja kako nadaljevati, kaj so naše ključne prednosti ter katere sisteme bomo uporabljali pri sebi in katere »v oblaku«. Pri tem bo v pomoč seznam 8 pravil oziroma korakov, ki jih moramo narediti:
- Pripraviti prehod na tekočinsko hlajenje IKT opreme, ob tem pa upoštevati visoke, do sedaj neobičajne temperaturne režime hladilnega medija.
- Otresti se strahu pred preseganjem obstoječih paradigem.
- Novim potrebam UI prilagoditi vire in celotne napajalne sisteme.
- Prenoviti zasnovo in arhitekturo sistemskih omar ter vrsto opreme, da omogočimo nameščanje novih sistemov ter doseganje ustreznih delovnih pogojev.
- Preveriti alternative za oskrbno infrastrukturo napajanja in hlajenja ter ju prilagoditi novim delovnim pogojem.
- Načrtovati možnost skaliranja oskrbne infrastrukture glede na nove potrebe.
- Novim pogojem dela prilagoditi storitve zagotavljanja delovanja oskrbne infrastrukture.
- Prilagoditi oziroma posodobiti celoten poslovni pristop.
Vsi zgoraj našteti koraki, pa tudi drugi izzivi, vprašanja in dileme, povezane z umetno inteligenco, tvorijo fokus strokovnega srečanja NTRsync, ki bo 26. marca v Mariboru. Vabilu nanj so se odzvali najuglednejši evropski strokovnjaki s področja informacijskih tehnologij in umetne inteligence ter predstavniki vodilnih globalnih ponudnikov najnaprednejših rešitev, ki omogočajo izkoriščanje UI sistemov. Udeležencem srečanja bodo predstavili napredne in stroškovno učinkovite strategije, ki omogočajo optimalno implementacijo UI v lastna IT okolja. V okviru srečanja pa bo udeležencem na voljo tudi ekskluziven obisk enega prvih slovenskih hibridnih podatkovnih centrov s superračunalnikom Vega. Ogled pod strokovnim vodstvom strokovnjakov, ki so sodelovali pri njegovem načrtovanju in vzpostavitvi, bo ponudil edinstveni vpogled v realno delovanje AI-ready infrastrukture.
VIR: Teme Evropskega parlamenta, 2020; spletni portal Evropskega parlamenta:
https://www.europarl.europa.eu/topics/sl/article/20200827STO85804/kaj-je-umetna-inteligenca-in-kako-se-uporablja-v-praksi

